Introduction:
For this particular project, we set out to see if we could predict a movies rating based on the content of the user reviews. In particular we sought out to determine what features are most prevelant in movies that are rated highly.
The dataset we used to train our model on was user reviews for the top 250 rated IMDB movies. We scraped the data from the IMDB website and also pulled in extra movie data from Rotten Tomatoes and Metacritic. Once we cleaned & split the data into our training and testing subsets, we used Random Forest Regression to fit the model and predict our IMDB ratings for our test set.
Dataset:
The first order of business was obtaining the top 250 movies from IMDB’s database. To accomplish this we used the IMDBpie module, which allowed us to collect the top 250 rated movies into dataframe. While, this was very easy, the information included with the IMDBpie module was very limited. It consisted of the movie rating, IMDB unique ID, movie title, type of movie and year. Not nearly enough information to build a good model around.
In order to supplement this data we used the Requests and BeautifulSoup modules to extract movie data from the OMDB API. The below code shows how we pulled the infromation.
# For each movie title pull extra data from OMDB API
top_250_list = []
for t in t_const:
payload = {'i':t,'plot':'short','r':'json', 'tomatoes':'True'}
URL = 'http://www.omdbapi.com/' # base URL
r = requests.get(URL, params=payload)
top_250_list.append(r.json())After we pulled the information, we compiled our new information into a new dataframe. Then merged our original dataframe and our new dataframe on the IMDB unique ID.
After we pulled this information we dropped a number of columns that would have no impact on IMDB rating or were repetitive, such as URLs, Images and repetitive dates. The resulting dataframe contained the following columns.
| Column | Type | Description |
|---|---|---|
| Plot | Text | Description of plot |
| Rated | Text | Movie rating |
| Title | Text | Title name |
| DVD | Date | Date movie came to DVD |
| Genre | Text | CSV of genre types |
| Language | Text | CSV of languages |
| Country | Text | CSV of countries |
| BoxOffice | Text | Gross $ values of box office sales |
| Runtime | Text | Movie run time |
| tomatoReviews | Int | # of Rotten Tomato reviews |
| imdbID | Text | Unique movie ID |
| Metascore | Int | Metacritic Scores |
| Year | Int | Year movie was released |
| imdbRating | Int | IMDB rating 0-10 |
| tomatoUserReviews | Int | # of user reviews from Rotten Tomatoes |
| imdbVotes | Int | # of IMDB user votes for a movie |
| Production | Text | Movie studio |
| Reviews | Text | User reviews on IMDB |
Data Cleaning:
The downside to pulling all this extra information for the movies is that now all of the data is in a text format. We converted the Metascore, tomatoReviews, tomatoUserReviews, Runtime, and imdbVotes columns to Int values. The Released column was converted to datetime. There was one movie in the IMDB top 250 that did not have information on tomatoReviews or tomatoUserReviews. We used the mean values from these columns to fill the N/A value.
In addition, a number of the studios in the Production column were slightly misspelled or put under various names. For example, the data had both Twentieth Century Fox and 20th Century Fox as production studios. To combine these results so that we’re able to accurately count the films by Studio, we used some regular expressions to replace values in the Productions column.
replacements = {
'Production': {
r'20th Century Fox Film Corporat': '20th Century Fox',
r'Buena Vista.*': 'Buena Vista Pictures',
r'Disney.*': 'Disney',
r'Dream[Ww]orks.*': 'DreamWorks',
r'Twentieth Century Fox.*': '20th Century Fox',
r'Warner Bros\..*': 'Warner Bros.',
r'Walt Disney': 'Disney',
r'Hollywood/Buena Vista Pictures': 'Buena Vista Pictures',
r'Sony Pictures.*': 'Sony Pictures',
r'The Weinstein Co.*': 'The Weinstein Co.',
r'UTV.*': 'UTV Motion Pictures',
r'United Artists.*': 'United Artists',
r'Universal.*': 'Universal Pictures',
r'Paramount.*': 'Paramount Pictures',
r'Orion.*': 'Orion Pictures',
r'Newmarket Film.*': 'Newmarket Film Group',
r'Miramax.*': 'Miramax Films',
}
}
top_250_trimmed_df.replace(replacements, regex=True, inplace=True)
top_250_trimmed_df.groupby('Production', sort=True).count()Analysis:
Once we had all the columns with the right datatypes, we wanted to look at the reviews column to pull out common words that may be predictive of a movies rating. For this we used CountVectorizer from the popular ML library scikit-learn. Since we were pulling data from an HTML document, we had to filter some top words that were HTML artifacts, such as “class”, “href”, “div” and others. In addition there were numerous generic, non-descriptive words that should apply to every movie and thus would not be useful, such as “movie”, “film” or “character”. Once we filtered out these words, we selected the top 6 most frequent words from the training review set. From the training dataset, the most frequent descriptive words were “best”, “great”, “life”, “good”, “love” and “action”.
We were now able to combine our newly created dataframe with the original dataframe to start putting together a predictive model.
The final processing step before modeling, was normalizing our training data using StandardScaler. Once this was complete we fit the RandomForestRegressor to our training dataset and used that to predict the values from our test dataset.
Results:
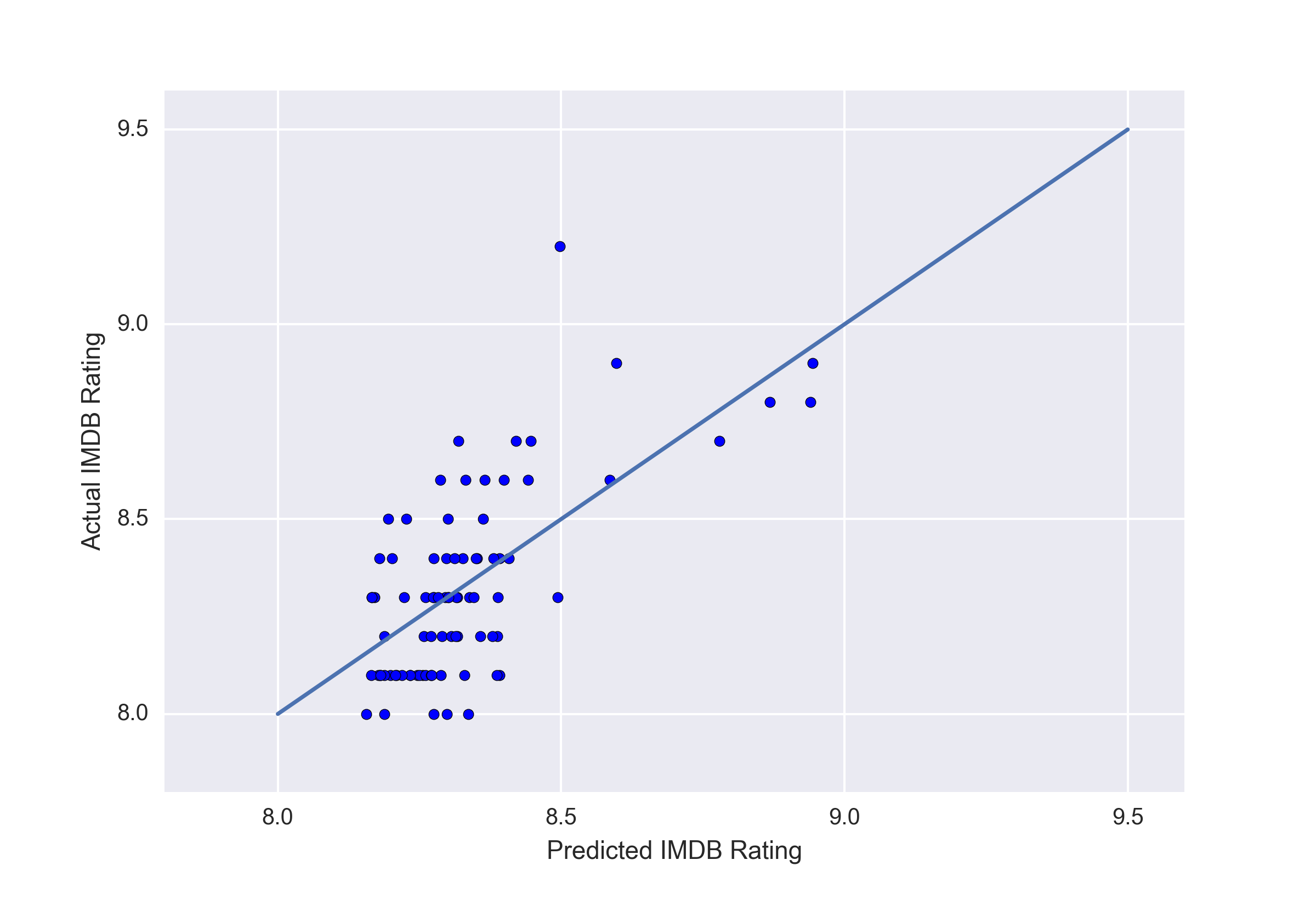
The model we fit showed that imdbVotes, tomatoReviews and released date were features that had the greatest importance in determining imdbRating. The model we fit did a very good job with a MSE of 0.0326 and MAE of 0.142.
Next Steps:
We were able to pull information on Actors, Directors, Awards and Plot summaries that we could pull additional features from. Given some additional time we would likely look at